Airbnb Brandometer: Powering Brand Perception Measurement on Social Media Data with AI
Airbnb Brandometer: Powering Brand Perception Measurement on Social Media Data with AI
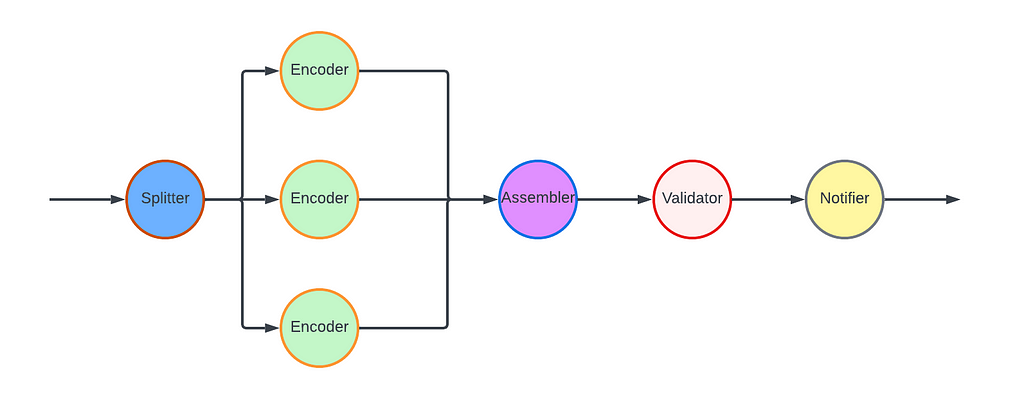
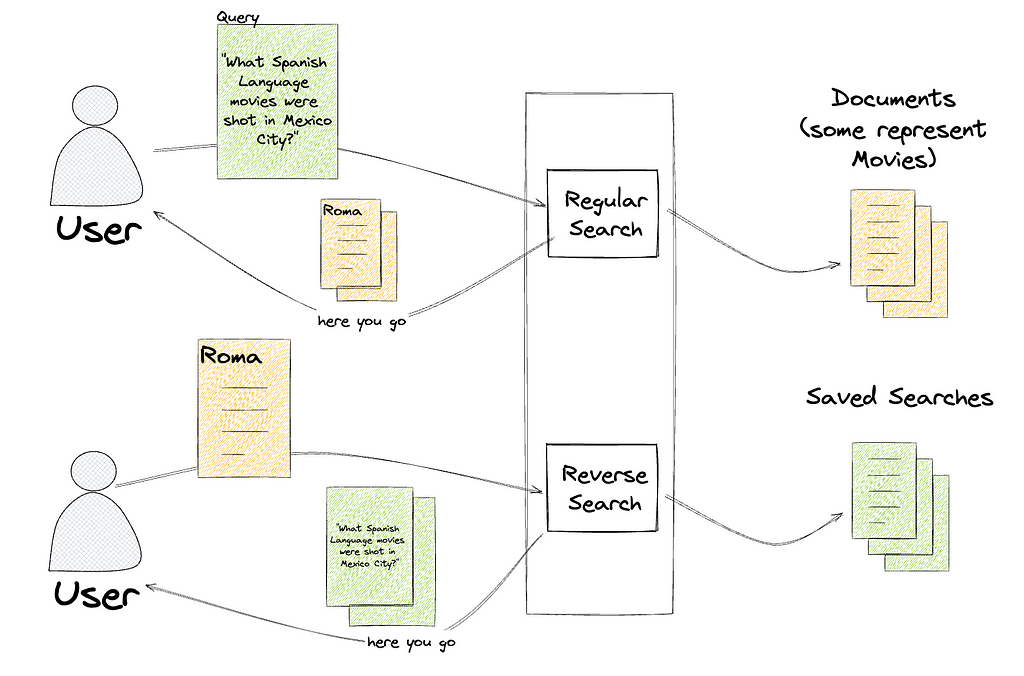
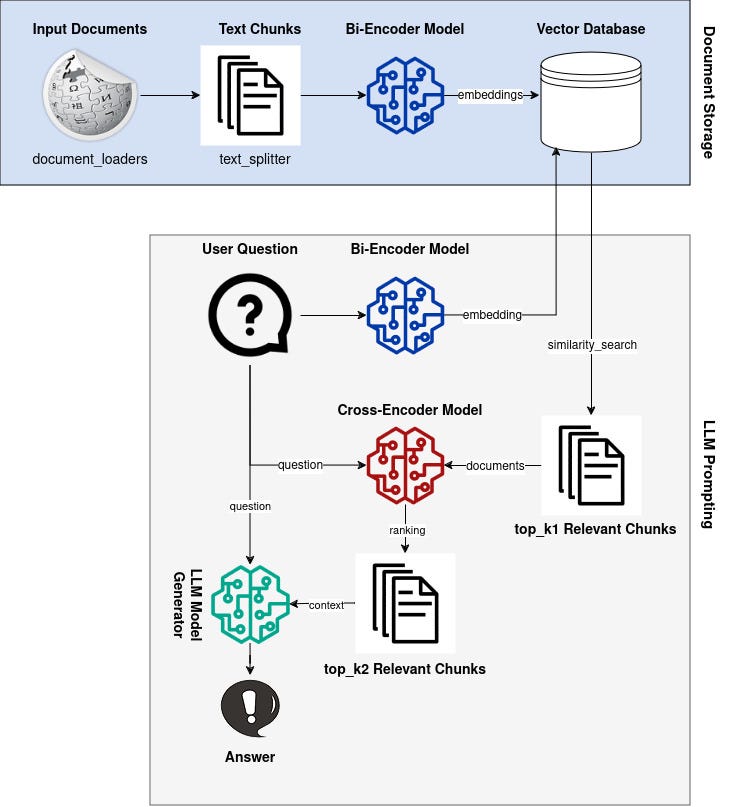
How we quantify brand perceptions from social media platforms through deep learningBy Tiantian Zhang, Shuai Shao (Shawn)IntroductionAt Airbnb, we have developed Brandometer, a state-of-the-art natural language understanding (NLU) technique for understanding brand perception based on social media data.Brand perception refers to the general feelings and experiences of customers with a company. Quantitatively, measuring brand perception is an extremely challenging task. Traditionally, we rely on customer surveys to find out what customers think about a company. The downsides of such a qualitative study is the bias in sampling and the limitation in data scale. Social media data, on the other ha…
6 days, 23 hours назад @ medium.com