Your request has been blocked due to a network policy.
If you're running a script or application, please register or sign in with your developer credentials here.
Additionally make sure your User-Agent is not empty and is something unique and descriptive and try again.
if you're supplying an alternate User-Agent string, try changing back to default as that can sometimes result in a block.
If you think that we've incorrectly blocked you or you would like to discuss easier ways to get the data you want, please file a ticket here.
3 часа назад @ reddit.com































![[Перевод] Как устроен Codex](https://habrastorage.org/getpro/habr/upload_files/2d5/201/d21/2d5201d21fc2668698313b78c5a82624.jpg)






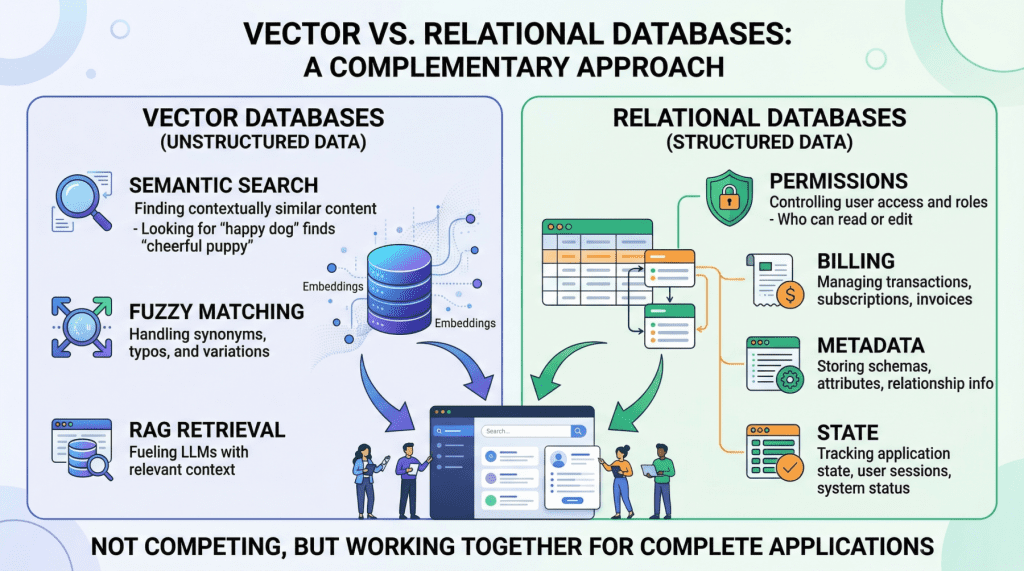
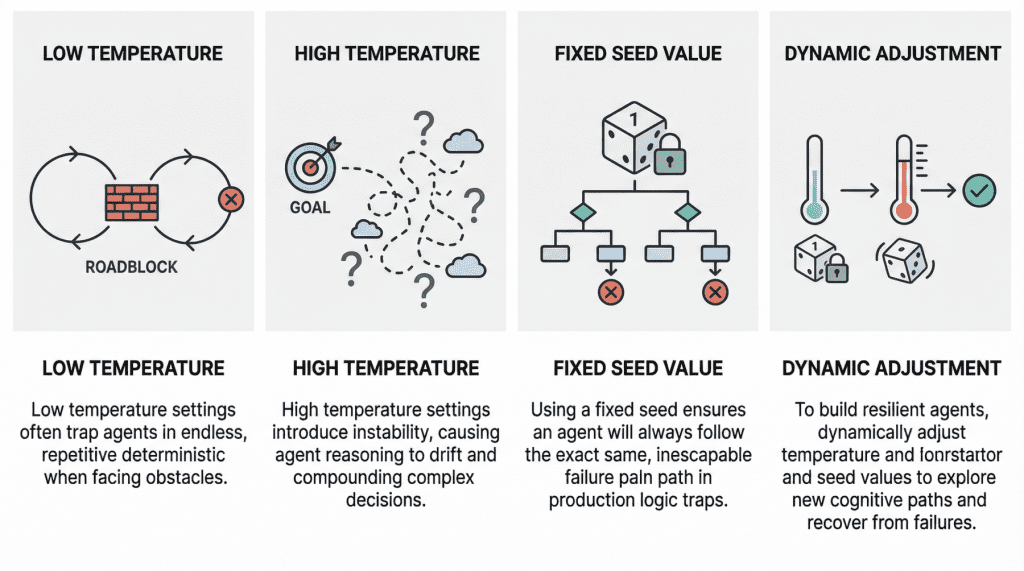
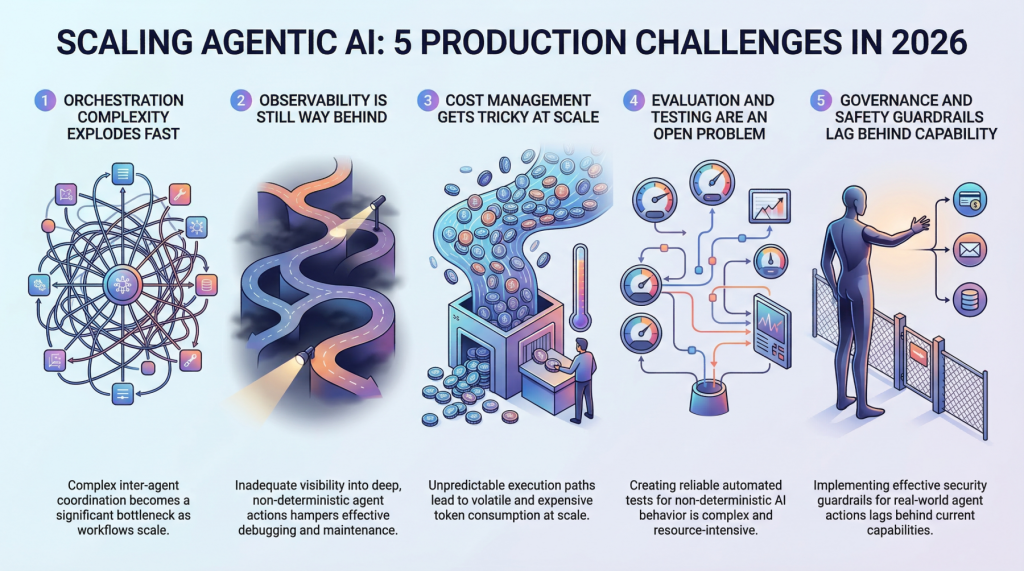

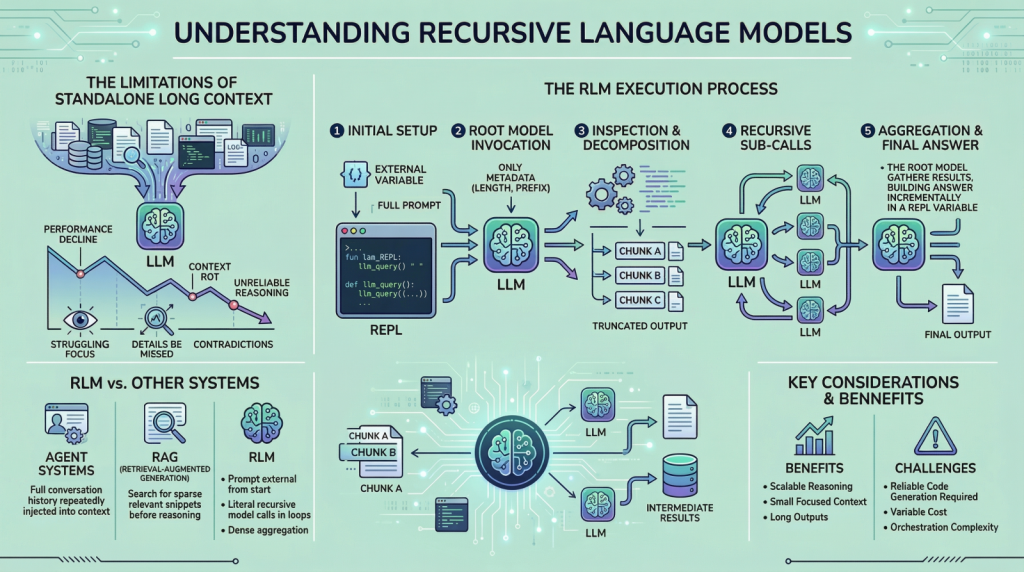


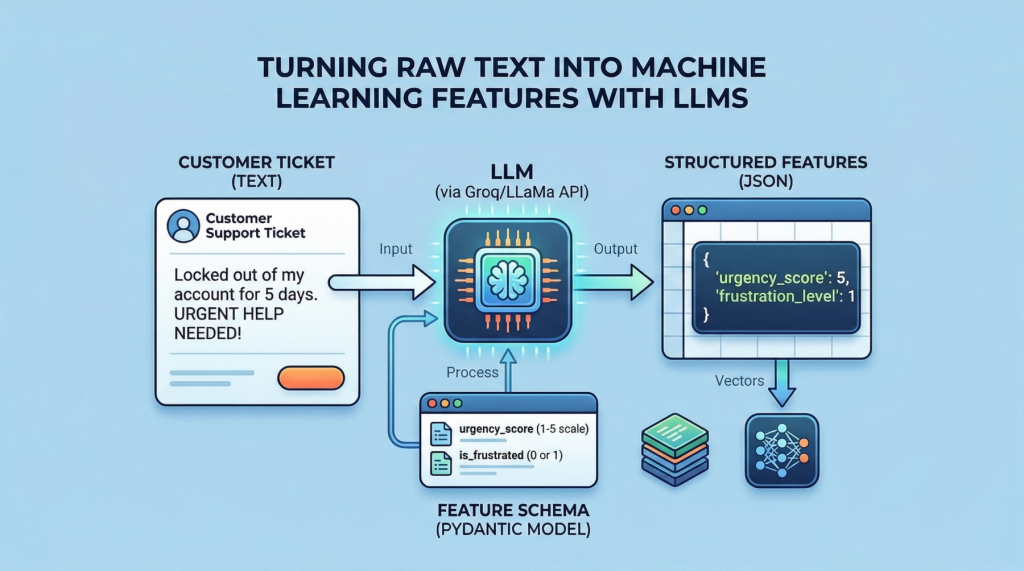
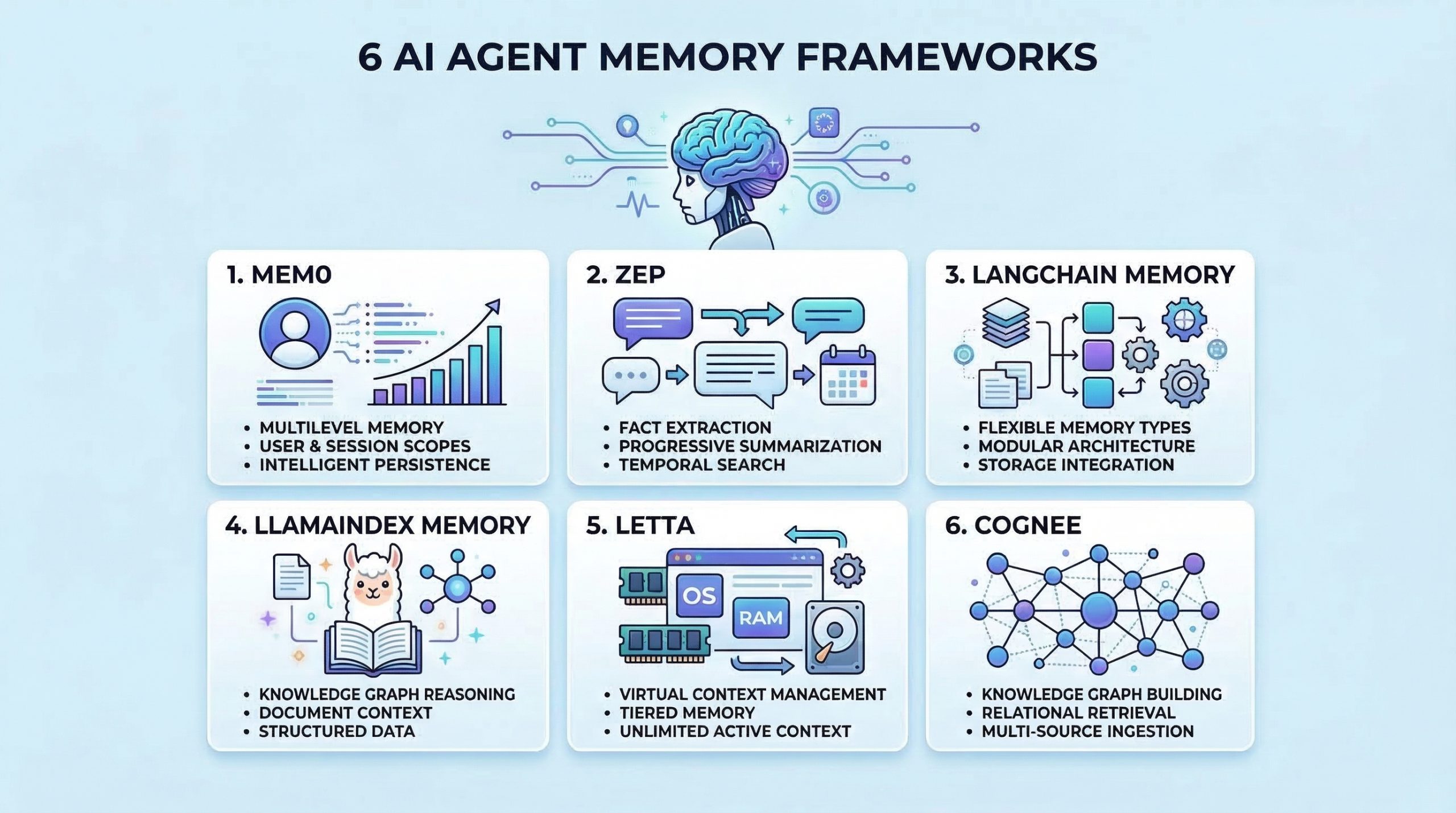
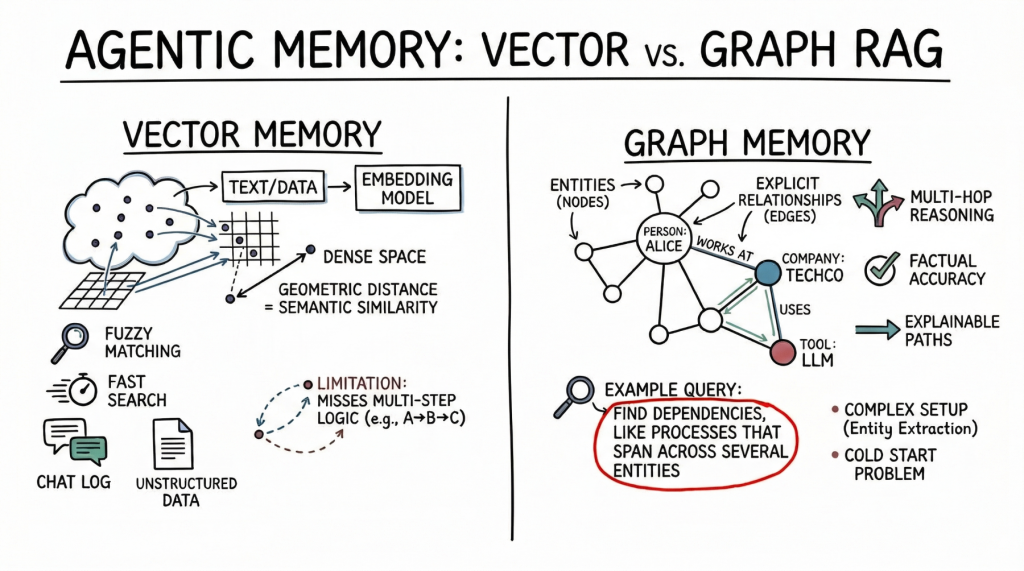








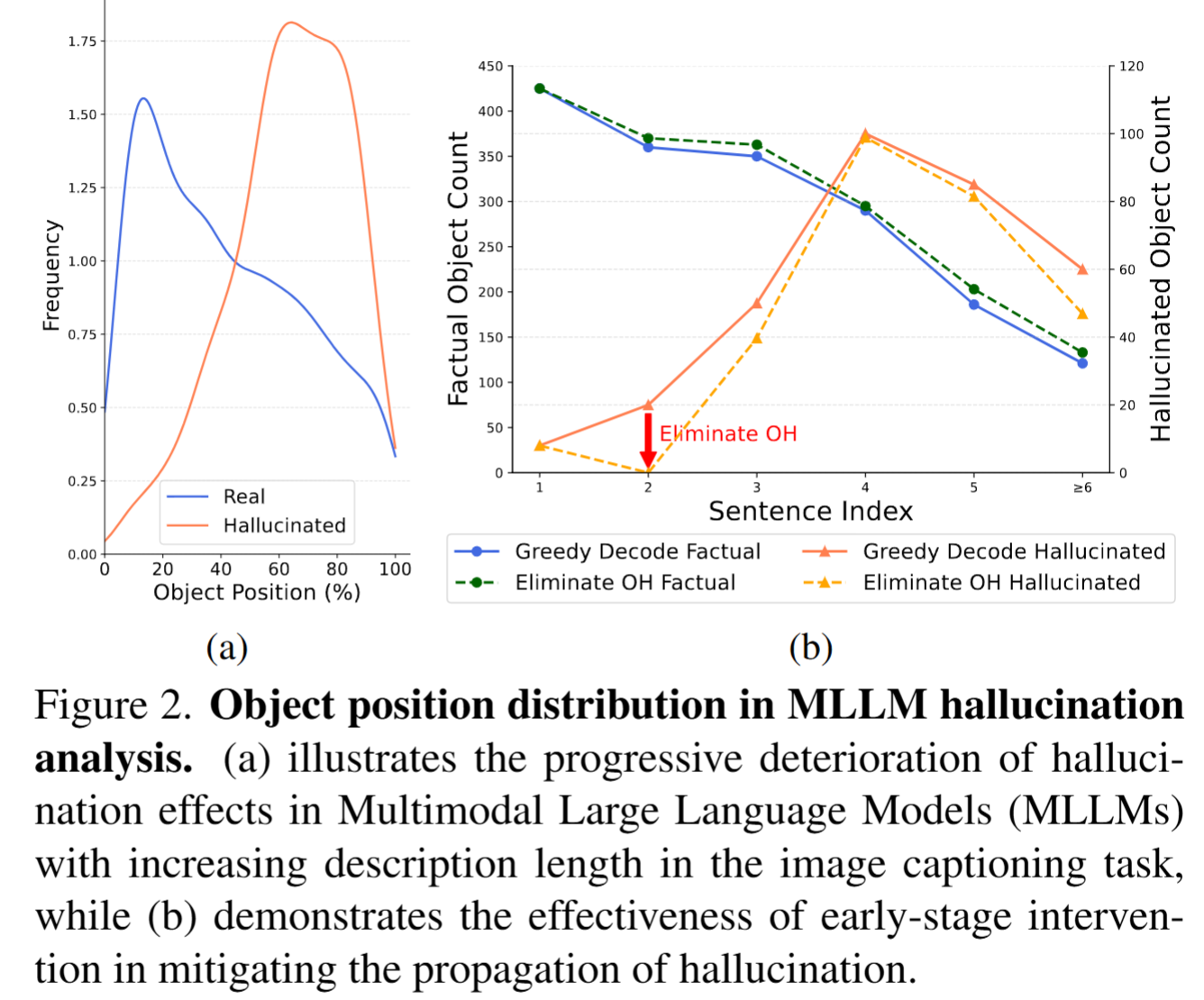















































































































![[Paper Analysis] The Free Transformer (and some Variational Autoencoder stuff)](https://i.ytimg.com/vi/Nao16-6l6dQ/maxresdefault.jpg?sqp=-oaymwEmCIAKENAF8quKqQMa8AEB-AH-CYAC0AWKAgwIABABGHIgPShAMA8=&rs=AOn4CLCCEXG65dygUjCUjktnX7tvu0mMGQ)
![[Video Response] What Cloudflare's code mode misses about MCP and tool calling](https://i.ytimg.com/vi/0bpYCxv2qhw/maxresdefault.jpg?sqp=-oaymwEmCIAKENAF8quKqQMa8AEB-AH-CYAC0AWKAgwIABABGGUgZShlMA8=&rs=AOn4CLBR8X7VGdO9ZvdO-QBw3jtTUdf9jw)
![[Paper Analysis] On the Theoretical Limitations of Embedding-Based Retrieval (Warning: Rant)](https://i.ytimg.com/vi/zKohTkN0Fyk/maxresdefault.jpg?sqp=-oaymwEmCIAKENAF8quKqQMa8AEB-AH-CYAC0AWKAgwIABABGGYgZihmMA8=&rs=AOn4CLCrV5gwZvDK4dpEK4MdD2mchKcYRQ)